PostgreSQL Multi-Active Replication - Part 1: An Introduction

Disclaimer: The postings on this site are my own and don’t necessarily represent my current or any previous employer’s positions, strategies or opinions.
This article is an introduction to a series covering multi-active replication options with PostgreSQL. You will learn why a multi-active setup might be desirable and also that it is anything but straightforward to implement with PostgreSQL. The series will cover various approaches and their trade-offs with each part providing a deep dive into one of the approaches. Eventually you will be able to understand, which approach could be the right fit for your scenario or if you should tread the multi-active path with PostgreSQL at all.
PostgreSQL Replication
PostgreSQL is a powerful, open-source object-relational database system with over 30 years of active development. It has earned a strong reputation for its robustness, scalability, and performance. Replication stands out as a critical feature for operating enterprise-grade applications using PostgreSQL. It is a method of copying and maintaining database objects, such as tables, in multiple database instances. It is fundamental for ensuring data availability, durability, and fault tolerance within database systems.
PostgreSQL offers two foundational replication strategies: physical and logical replication. Physical replication involves copying the byte-by-byte state of a primary database to a secondary server, which is ideal for creating an exact replica for failover scenarios, ensuring high availability. On the other hand, logical replication transmits data changes at the level of individual records, offering greater flexibility regarding selective data sharing and the possibility of transformations during replication. While physical replication is inherently unidirectional, logical replication opens up avenues for more complex configurations — like multi-active replication.
Why Multi-Active Replication?
Multi-active (sometime also called multi-primary or multi-master) replication is a sophisticated replication technique that facilitates simultaneous data replication across multiple active (primary) nodes. In this model, every node is capable of accepting write operations and replicating changes to other nodes. This approach contrasts with traditional primary-secondary replication, where write operations are exclusively handled by the primary node.
The need for multi-active replication arises in scenarios that require global high-availability infrastructure with load balancing and minimal read/write latency. For example, organizations operating on a global scale may need instances of their databases in different geographical locations to serve local users more efficiently. Multi-active replication enables organizations to keep read/write nodes closer to customers in their regions. Not only does this setup helps to reduce latency by providing faster access to data, but it also ensures that updates made in one location are replicated across the global infrastructure, thereby keeping the data (eventually) consistent and up to date.
Multi-active replication’s value becomes even more noticeable in the event of a complete regional failure. With this replication model in place, another region can take over seamlessly, negating the need for the typical standby-to-primary promotion process characteristics of traditional replication strategies. This capability ensures continuous availability and operational resilience, as users can be rerouted to the functioning region without experiencing significant downtime or service disruption. Thus, the architecture not only facilitates local data sovereignty and efficiency but also provides a robust failover mechanism, making the system as a whole more fault-tolerant and reliable.
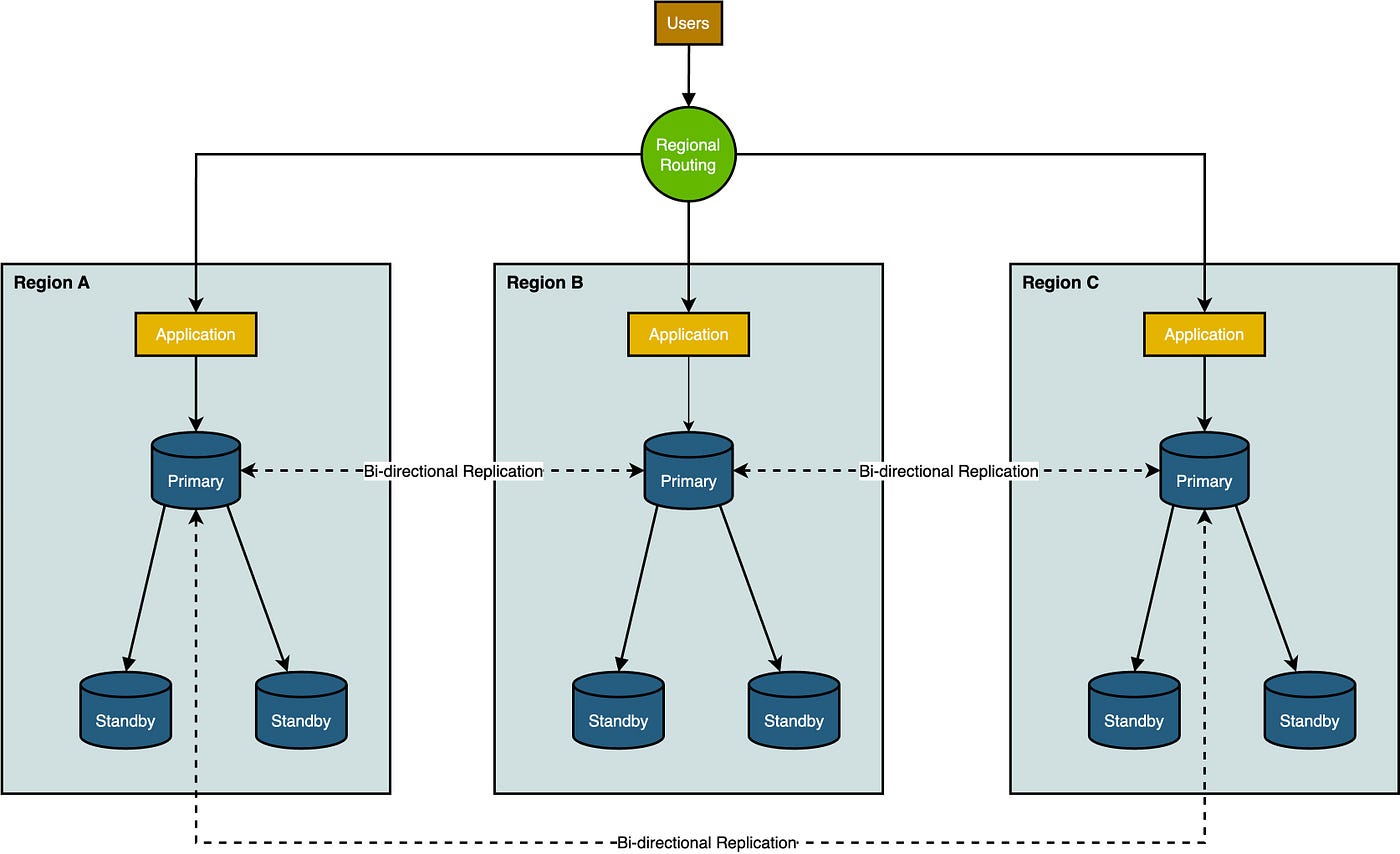
Multi-Active Replication Considerations
While multi-active replication offers numerous potential benefits in terms of high availability, load balancing, and reduced latency, it’s crucial to maintain realistic expectations regarding its implementation, especially in the context of PostgreSQL. As the CAP theorem indicates, there is an inherent trade-off between consistency, availability, and partition tolerance. Multi-active replication, by its nature, may lead to scenarios where data consistency is less stringent compared to traditional replication models. This is a significant consideration for systems where data integrity is paramount.
Furthermore, each multi-active replication solution comes with its own set of limitations and trade-offs. These may include complexities in conflict resolution, increased operational overhead, and potential performance impacts. Especially in PostgreSQL, implementing a multi-active setup is not straightforward and involves navigating these inherent trade-offs.
Currently, there is no one-size-fits-all solution for multi-active replication in PostgreSQL. Implementing such a system requires a thorough understanding of the specific requirements and constraints of your organization’s infrastructure and the willingness to manage the additional complexities that come with a multi-active environment. It’s essential to weigh these factors carefully and consider whether the advantages of multi-active replication align with your organization’s needs and capabilities. In some cases, alternative strategies may provide a more suitable balance between consistency, availability, and operational simplicity.
Landscape of Bi-Directional Replication Solutions for PostgreSQL
As the need for multi-active replication in PostgreSQL has grown, so have the solutions available to implement it. Here’s a brief overview of the various approaches:
Native Capabilities with PostgreSQL 15 and 16
Starting with PostgreSQL 15, there have been significant enhancements to logical replication and the introduction of row-level filtering, which can be theoretically used to build a very simple multi-active replication setup. This native support continues to evolve with newer releases like PostgreSQL 16, offering additional origin filter functionality that is essential for loop-back prevention with multi-active replication. Still, the native support remains very limited.
BDR and PGLogical Extensions
Extensions like BDR (Bi-Directional Replication) and PGLogical provide more specialized mechanisms. These extensions offer a more out-of-the-box solution to the complexities of multi-active replication. Unfortunately, the free versions of the extensions are no longer being developed, and the new versions are only available in a paid variant, which is not a suitable option for everyone.
Change Data Capture (CDC) Approach
CDC tools like Debezium and Apache Pulsar allow for capturing changes in a database and propagating them to other systems. While they are not specifically designed for this purpose, they can be configured to replicate data between PostgreSQL instances for a multi-active scenario. However, the flexibility of this approach comes at a higher management and development cost.
Local-First Approach
A Local-First approach prioritizes the ability of local systems to operate independently while contributing to a global system. This method focuses on the autonomy of local instances, with synchronization occurring as a secondary process. While the Local-First approach is getting more popular not all solutions are mature and “battle-tested”. It fits well for mobile scenarios but might be not the best option for other use cases.
Upcoming Series Parts
Given the complexity and the multitude of approaches to multi-active replication, my co-author Oliver Rau and I have concluded that it is most beneficial not to condense this rich content into a single article. Instead, we’ve decided to divide it into a comprehensive series, each including detailed explorations of the various approaches. We believe this will allow us to provide more thorough, digestible insights and facilitate a better understanding. The final article will summarize the key takeaways from the series, compare the different approaches, and offer some final thoughts on the current options and limitations of building a multi-active replication system with PostgreSQL.
- Part 1: Introduction (this article)
- Part 2: Native replication in PostgreSQL 15 and 16
- Part 3: BDR and PGLogical
- Part 4: Change Data Capture Approach
- Part 5: Local-First Approach
- Part 6: Overall Conclusion
To maintain a dynamic and engaging discourse, we will alternate the publication of each part, with the subsequent article set to be presented by Oliver Rau.
It is also important to note that our series will primarily concentrate on open-source solutions. This focus ensures that we cover the most accessible and adaptable technologies available, providing our audience the practical empowerment to implement and adapt these solutions in their environments. Nevertheless, we will touch on some closed-source commercial solutions and explicitly mention if this should be the case.
